需求描述
有三个任务,jobA、jobB、jobC需要部署在两台服务器A、B上,
- 其中jobA操作数据库,所以jobA一次只能在一台服务器上运行,不能在服务器A、B上同时运行;
- jobB虽然不操作数据库,但也有相同需求,就是不能同时在两台服务器上运行;
- jobC可以同时在两台服务器上运行;
则jobA和jobB需要用到Quartz集群配置,jobC需要非集群配置。
Quartz的集群是依靠数据库实现的,是依靠数据库来监控到底是哪个quartz去执行了这个任务,然后让别的quartz不再执行这个任务。
我们需要先去Quartz官网下载相应版本的Quartz,然后解压,在/docs/dbTables文件夹下,会有各个数据库版本的sql文件,我们用的是mySQL数据库,所以我选择的是tables_mysql_innodb.sql文件:
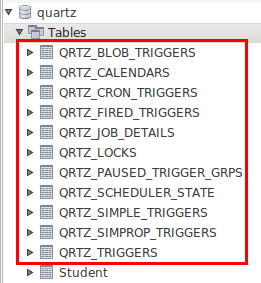
新建数据库quartz,然后运行tables_mysql_innodb.sql文件,会创建11张表,Quartz就是靠这11张表来实现集群的。
接下来就是创建Gradle项目,实现Quartz集群配置。
创建Gradle项目
首先新建Gradle项目:
然后填写GroupId和ArtifactId:
下一步需要将前两项勾选上,这样IDEA会帮我们创建相应的项目文件夹:
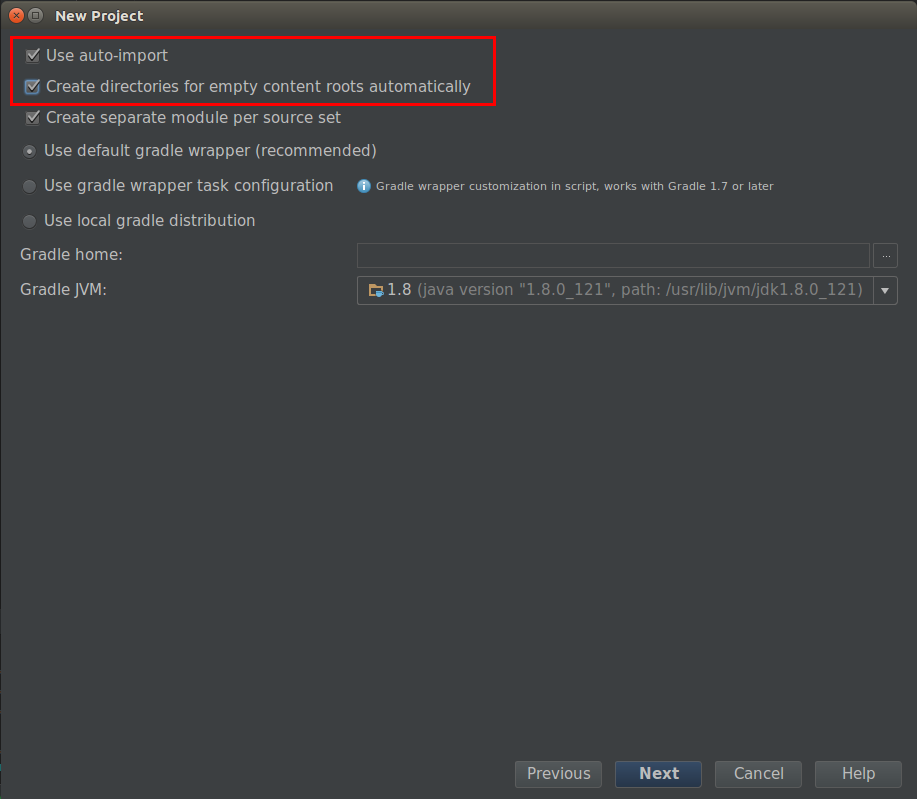
这样一个空的项目就搭建起来了。
配置build.gradle
要想使用Quartz需要先添加相应依赖,我们实现的Quartz是要结合Spring的,所以也要引进Spring的相应依赖:
quartz集群与非集群配置
在同一个项目同时实现集群和非集群,就需要写两个调度配置,然后配置调度器,设置特定时间启动,然后再配置相应的job。具体配置如下:
非集群配置
|
|
将使用非集群的任务调度器放在<property name="triggers">的<list>里,然后再配置触发器和相应的job:
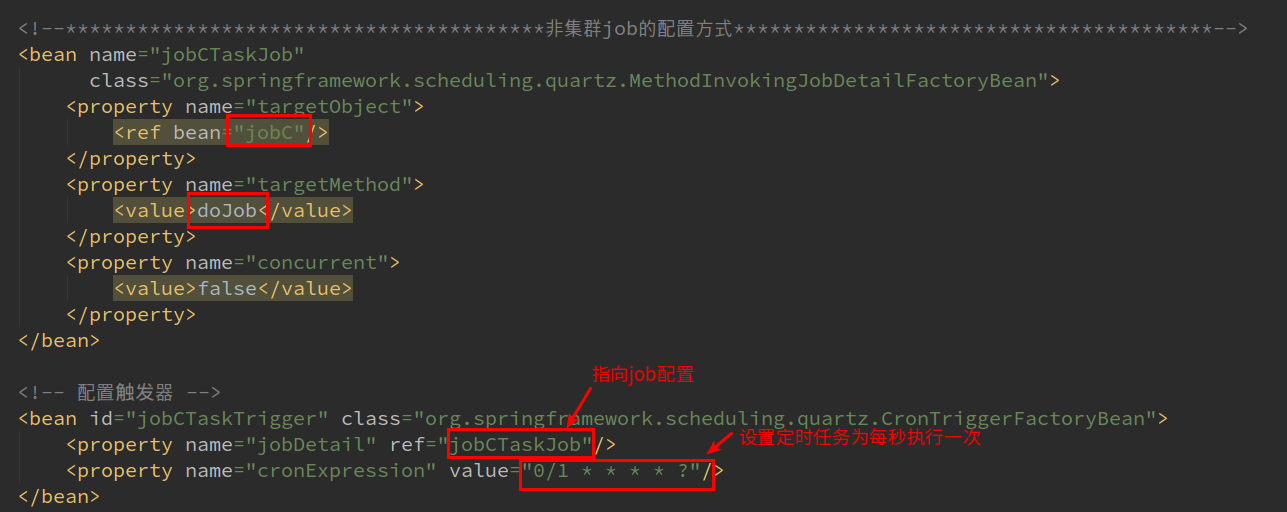
首先触发器的cronExpression定义job的触发时间,jobDetail是job的实例,JobDetail是在Job被添加到Scheduler时由应用程序创建的,它包含了关于Job的各种属性信息。当触发器激活时,与他关联的JobDetail 被加载,然后就会找到本例中的jobC类的doJob方法并执行。
集群配置
本例中是将Quartz的一些集群配置直接整合到xml文件里了,也可以在quartz.properties里配置。

因为我们是用数据库来实现集群的,所以需要将“org.quartz.jobStore.class”值设置为“org.quartz.impl.jdbcjobstore.JobStoreTX”,如果想使用内存存储,只需要将其值设置为“org.quartz.simpl.RAMJobStore”即可。但是内存存储无法实现持久化。
“org.quartz.jobStore.isClustered”的值设置为“true”,即代表该Scheduler下的job参与到一个集群当中。

触发器的配置跟非集群的配置相同,配置定时时间和job实例。
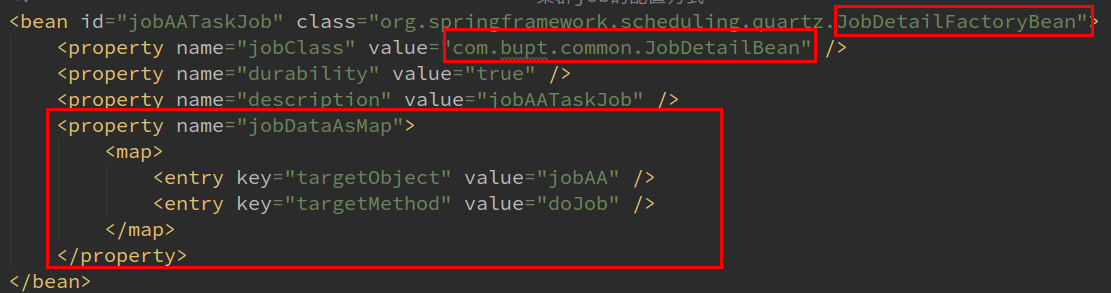
在Spring中使用Quartz有两种方式实现:
- 利用JobDetailBean包装QuartzJobBean子类(即Job类)的实例。
- 利用MethodInvokingJobDetailFactoryBean工厂Bean包装普通的Java对象(即Job类),是在配置文件里定义任务类和要执行的方法,类和方法仍然是普通类。
具体说明:
1、采用第一种方法必须要继承QuartzJobBean,实现 executeInternal(JobExecutionContext jobexecutioncontext)方法,此方法就是被调度任务的执行体,然后将此Job类的实例直接配置到JobDetailBean中即可。
2、采用第二种方法 创建Job类,无须继承父类,直接配置MethodInvokingJobDetailFactoryBean即可。但需要指定一下两个属性:
targetObject:指定包含任务执行体的Bean实例。
targetMethod:指定将指定Bean实例的该方法包装成任务的执行体。
由于集群需要把定时任务的信息写入表,需要序列化,但MethodInvokingJobDetailFactoryBean 不能序列化,会报错。所以我们采用第一种方式。
首先重写JobDetailBean类:
|
|
所以在配置job的时候,需要指定jobClass,指向重写的类。
主函数
|
|
首先指定配置文件,然后在引入到JobDetailBean里,这样程序就会读取配置文件,执行调度器,触发触发器,加载关联的JobDetail。
job类
jobAA
|
|
jobBB
|
|
jobC
|
|
运行结果
再新建一个项目,项目结构和代码跟上面讲的一模一样,然后运行,根据输出结果会发现,jobAA和jobBB每次只会在一台机器上运行,而jobC两台机器同时运行。
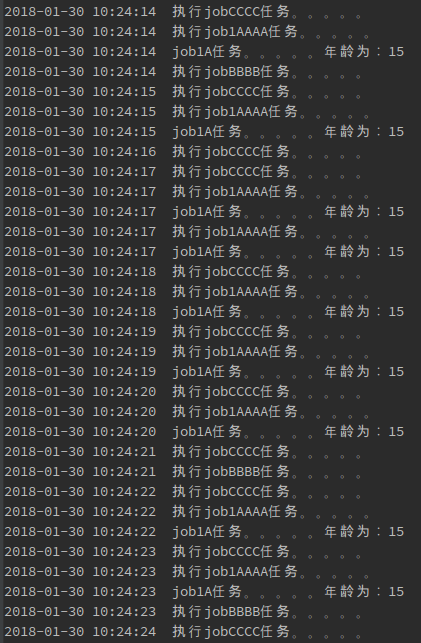
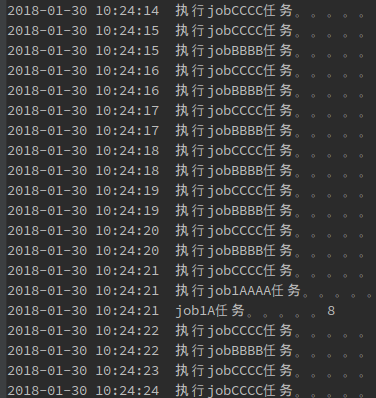
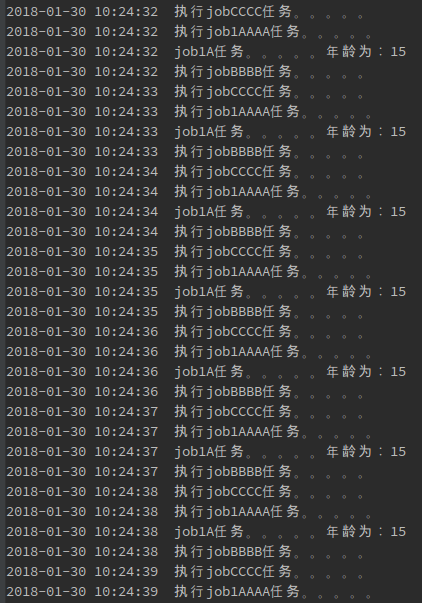
从上图也可以看出,当我停掉一台机器时,另一台会马上把jobAA和jobBB的任务结果来继续执行。
完整代码在我的github上https://github.com/ily11/quartzCluster